Documentation Index
Fetch the complete documentation index at: https://forge-64364c0e.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Convert (05)
Convert SafeTensors models (HuggingFace format) to GGUF files compatible with llama.cpp, Ollama, LM Studio, and other GGUF-based runtimes.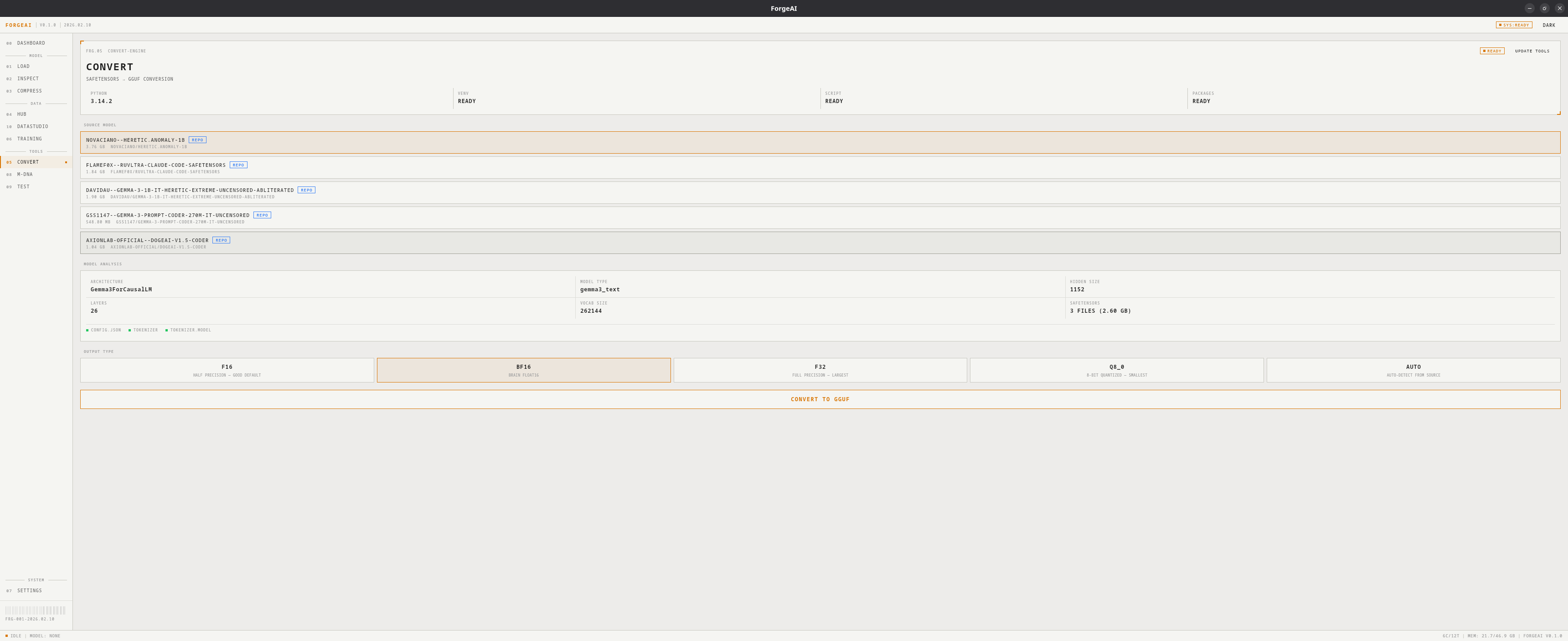
Requires Python 3.10+ and a one-time dependency setup (~500 MB). The convert environment is separate from the training environment and can be managed in Settings.
First-Time Setup
Install dependencies
Click INSTALL DEPENDENCIES — creates a virtual environment with
transformers, torch, safetensors, sentencepiece, protobufOutput Types
| Type | Description | Use Case |
|---|---|---|
| F16 | 16-bit float (default) | Best balance of size and precision |
| BF16 | Brain float 16 | Better precision for large models |
| F32 | Full 32-bit float | Maximum precision, largest file |
| Q8_0 | 8-bit quantized | Smaller output, slight quality loss |
| AUTO | Detect from source | Matches source precision |
Model Analysis
After selecting a source, ForgeAI shows:| Field | Description |
|---|---|
| ARCHITECTURE | Model architecture (e.g., LlamaForCausalLM) |
| HIDDEN SIZE | Embedding dimension |
| LAYERS | Number of transformer layers |
| VOCAB SIZE | Tokenizer vocabulary size |
| SAFETENSORS | Number of weight files |
config.json (required), tokenizer files, safetensors weights.
Workflow
Select source
Pick a SafeTensors repo from the list (downloaded via Hub) or click GO TO HUB