Documentation Index
Fetch the complete documentation index at: https://forge-64364c0e.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Test (09)
Run text generation on GGUF or SafeTensors models with real-time token streaming, 6 quick test presets, and full control over generation parameters.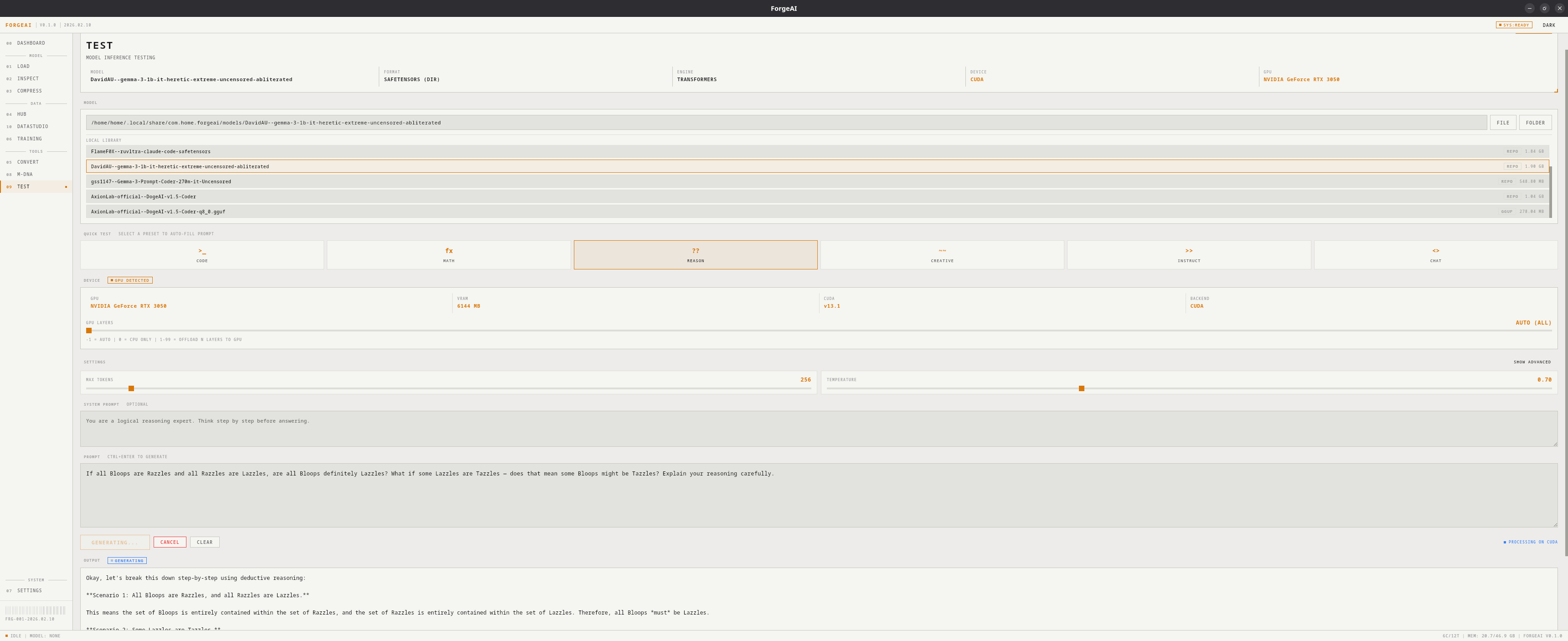
Model Selection
Manual Path
Type or paste a file/folder path
Browse
Click FILE or FOLDER to open system dialog
Use Loaded
Quick button for the currently loaded model
Local Library
Click a chip from your downloaded models
Quick Test Presets
Click a preset to instantly fill in a test prompt:| Preset | Prompt Theme | Tests |
|---|---|---|
| CODE | FizzBuzz in Python | Code generation ability |
| MATH | Word problem solving | Mathematical reasoning |
| REASON | Logic puzzle | Logical deduction |
| CREATIVE | Story writing | Creative writing |
| INSTRUCT | Step-by-step tasks | Instruction following |
| CHAT | Conversational | General chat ability |
Inference Engines
| Format | Engine | Device |
|---|---|---|
| GGUF | llama.cpp (llama-cli) | CPU or GPU |
| SafeTensors | HuggingFace Transformers | GPU (CUDA) → CPU fallback |
Generation Settings
| Parameter | Range | Default | Description |
|---|---|---|---|
| Max Tokens | 1–8192 | 256 | Maximum tokens to generate |
| Temperature | 0–2 | 0.7 | Randomness. 0 = deterministic |
| Top-p | 0–1 | 0.9 | Nucleus sampling threshold |
| Top-k | 1–100 | 40 | Top-k token sampling |
| Repeat Penalty | 1.0–2.0 | 1.1 | Repetition suppression |
| Context Size | 512–32768 | 2048 | Context window size |
| GPU Layers | -1 to 99 | -1 | Layer offloading (-1=auto, 0=CPU) |
System Prompt
Add a custom system message to guide model behavior (e.g., “You are a helpful coding assistant.”).Output
Tokens stream into the output panel in real time. After completion, a stats bar shows:| Stat | Description |
|---|---|
| TOKENS | Number of tokens generated |
| TIME | Total generation time |
| SPEED | Tokens per second |
| DEVICE | CPU or CUDA |
GPU Acceleration
- GGUF: Uses GPU if llama.cpp was installed with CUDA or Vulkan variant. GPU layers setting controls how many layers are offloaded to GPU.
- SafeTensors: Tries CUDA GPU first; falls back to CPU if out of memory.