Documentation Index
Fetch the complete documentation index at: https://forge-64364c0e.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Load (01)
The Load module imports AI models into ForgeAI. It parses model headers without reading the full file, extracting metadata, tensor maps, and architecture information in under a second.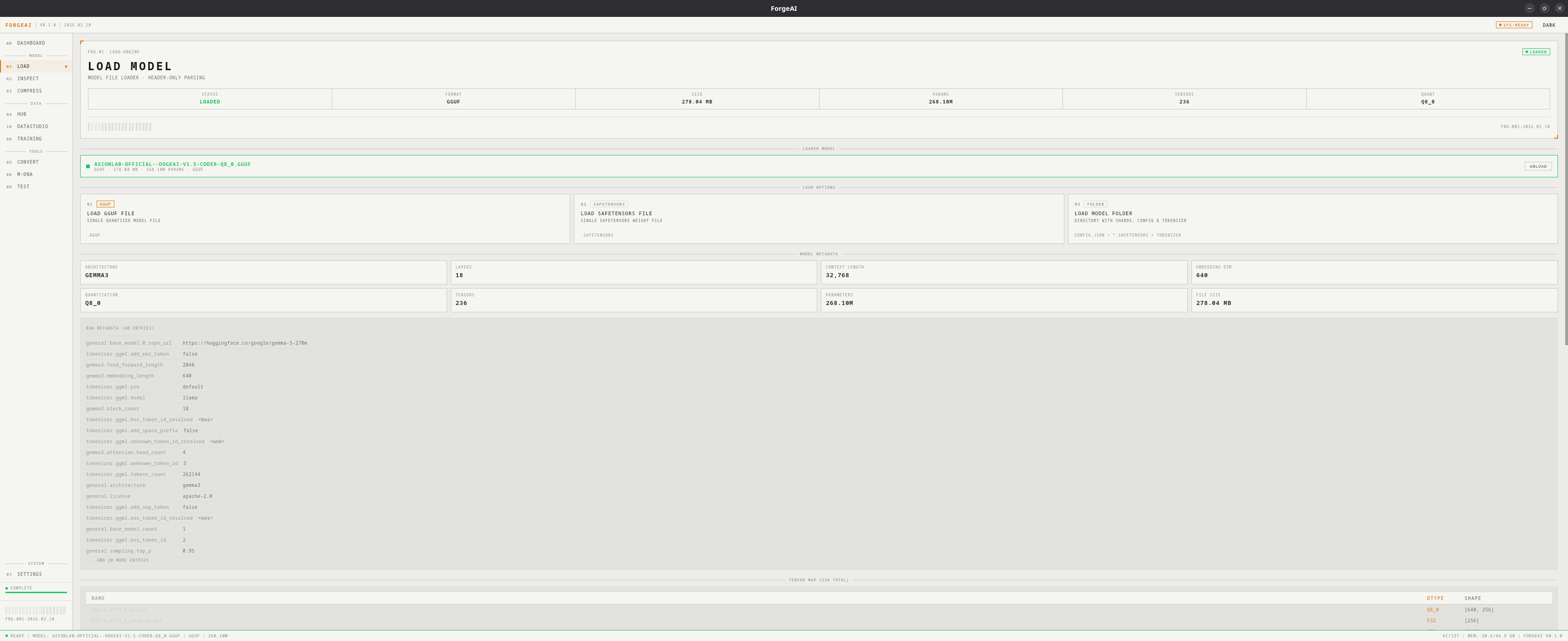
Load Options
GGUF File
Single
.gguf file — quantized models from the llama.cpp ecosystemSafeTensors File
Single
.safetensors file — HuggingFace model weightsModel Folder
Directory with
.safetensors + config.json — sharded HuggingFace modelsWhat Gets Parsed
On load, ForgeAI reads the model header and extracts:- Architecture (e.g., LlamaForCausalLM, MistralForCausalLM, Qwen2ForCausalLM)
- Layer count and context length
- Embedding dimensions
- Parameter count (computed from tensor shapes)
- Quantization type (GGUF only)
- Tensor map — names, dtypes, and shapes of all tensors
- Raw metadata — all key-value pairs from the model header
- Number of shards
- Presence of
config.json - Presence of tokenizer files
Hero Panel
| Field | Values |
|---|---|
| STATUS | IDLE, LOADING, LOADED, ERROR |
| FORMAT | GGUF or SAFETENSORS |
| SIZE | File size on disk |
| PARAMS | Parameter count (e.g., 7.24B) |
| TENSORS | Total tensor count |
| QUANT | Quantization type (e.g., Q4_K_M) |
Metadata Grid
After loading, a grid displays key model properties:| Field | Description |
|---|---|
| ARCHITECTURE | Model family (LlamaForCausalLM, etc.) |
| LAYERS | Number of transformer layers |
| CONTEXT | Maximum sequence length |
| EMBEDDING | Hidden dimension size |
| QUANT | Quantization type |
| TENSORS | Total tensor count |
| PARAMS | Parameter count |
| SIZE | File size on disk |
Tensor Map Preview
A table showing tensor names, dtypes, and shapes. For large models the preview is capped with a count of remaining tensors.Raw Metadata
A scrollable list of the first 20 metadata key-value pairs from the model header.Workflow
Review metadata
Header parsing takes under 1 second. Review model metadata, tensor map, and raw metadata.