Documentation Index
Fetch the complete documentation index at: https://forge-64364c0e.mintlify.app/llms.txt
Use this file to discover all available pages before exploring further.
Compress (03)
Quantize GGUF models to smaller sizes using llama-quantize. Preview estimated size, quality, and speed before running.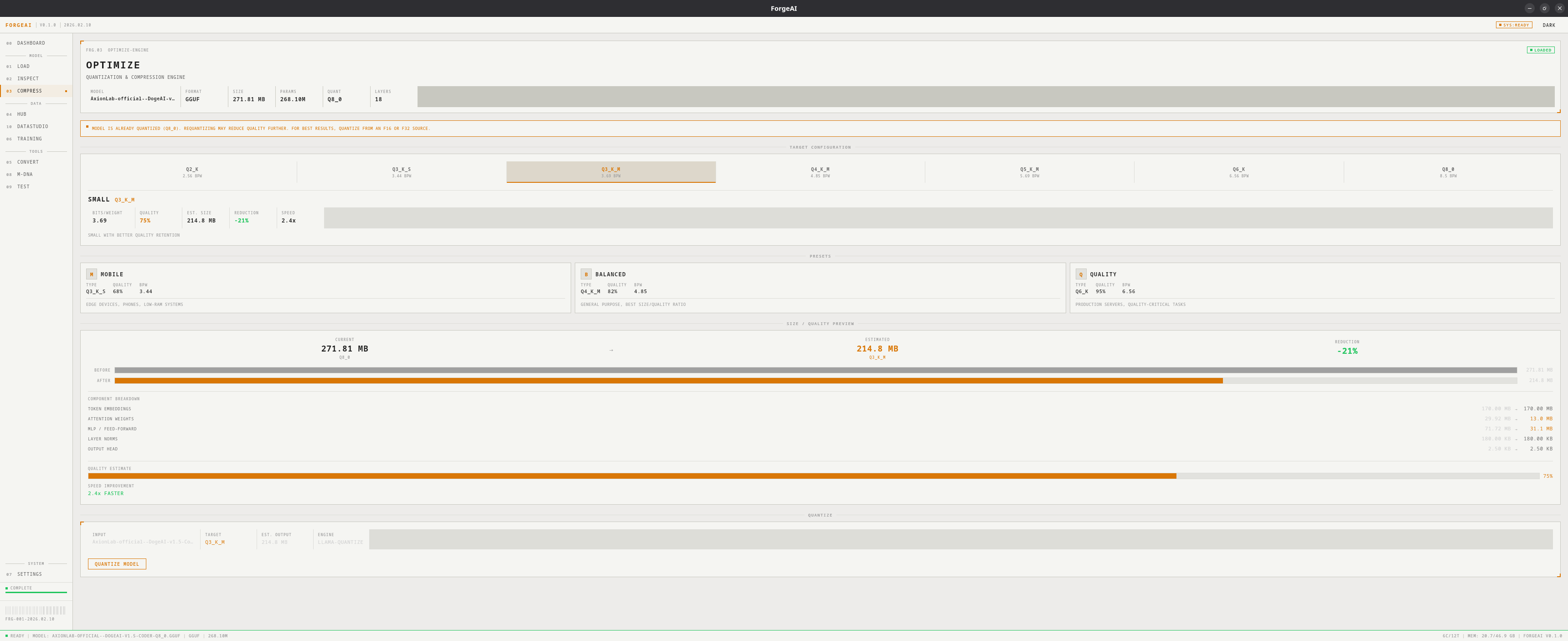
Requires a loaded GGUF model and llama.cpp tools installed (see Settings).
Quantization Levels
| Level | Type | Bits/Weight | Quality | Use Case |
|---|---|---|---|---|
| EXTREME | Q2_K | 2.63 | ~60% | Smallest possible, significant quality loss |
| TINY | Q3_K_S | 3.50 | ~68% | Very small, noticeable quality loss |
| SMALL | Q3_K_M | 3.91 | ~72% | Small with better quality |
| COMPACT | Q4_K_M | 4.85 | ~80% | Good balance for most use cases |
| BALANCED | Q5_K_M | 5.69 | ~87% | Recommended general purpose |
| HIGH | Q6_K | 6.56 | ~93% | Near-original quality |
| ULTRA | Q8_0 | 8.50 | ~98% | Minimal quality loss |
Presets
MOBILE
Q3_K_M — Edge devices, phones, low-RAM systems
BALANCED
Q5_K_M — General purpose desktops and laptops
QUALITY
Q8_0 — Production servers, quality-critical applications
Size & Quality Preview
Before quantizing, a preview shows:- Before/After file sizes with reduction percentage
- Component breakdown: attention, MLP, embeddings, output head, norms
- Quality estimate bar
- Speed improvement relative to original
Workflow
Load a GGUF model
Use the Load module to import a GGUF file